Crafting GBD-Net for Object Detection
This webpage provides details on our submission to the ILSVRC 2016 Challenge
ILSVRC 2016 Object Detection Challenge (Team: CUImage): Rank #1 in both provided training data track and additional training data track.
ILSVRC 2016 Object Detection from Video Challenge (Team: CUVideo): Rank #1 in Object detection/tracking from video with provided training data track, Rank #2 in Object detection from video with provided training data track.
Abstract
The visual cues from multiple support regions of different sizes and resolutions are complementary in classifying a candidate box in object detection. How to effectively integrate local and contextual visual cues from these regions has become a fundamental problem in object detection. In this paper, we proposal a gated bi-directional CNN (GBD-Net) to pass messages among features from different support regions during both feature learning and feature extraction. Such message passing can be implemented through convolution in two directions and can be conducted in various layers. Therefore, local and contextual visual patterns can validate the existence of each other by learning their nonlinear relationships and their close interactions are modeled in a much more complex way. It is also shown that message passing is not always helpful but dependent on individual samples. Gated functions are further introduced to control message transmission and their on-or-offs are controlled by extra visual evidence from the input sample. The effectiveness of GBD-Net is shown through experiments on three object detection datasets, ImageNet, Pascal VOC2007 and Microsoft COCO. This paper shows the details of our approach in wining the ImageNet object detection challenge of 2016, with source code provided online.
Contribution Highlights
- A new deep learning pipeline for object detection. It effectively integrates region proposal, feature representation learning, context modeling, and model averaging into the detection system. Detailed component-wise analysis is provided through extensive experimental evaluation. This paper also investigates the influence of CNN structures for the large-scale object detection task under the same setting. The details on our submission in winning the ImageNet Object Detection Challenge is provided in this paper, with source code provided online.
- A bi-directional network structure is proposed to pass messages among features from multiple support regions of different resolutions. With this design, local patterns pass detailed visual messages to larger patterns and large patterns passes contextual visual messages in the opposite direction. Therefore, local and contextual features cooperate with each other in improving detection accuracy. It shows that message passing can be implemented through convolution.
- We propose to control message passing with gate functions. With the designed gate functions, message from a found pattern is transmitted when it is useful in some samples, but is blocked for others.
Images
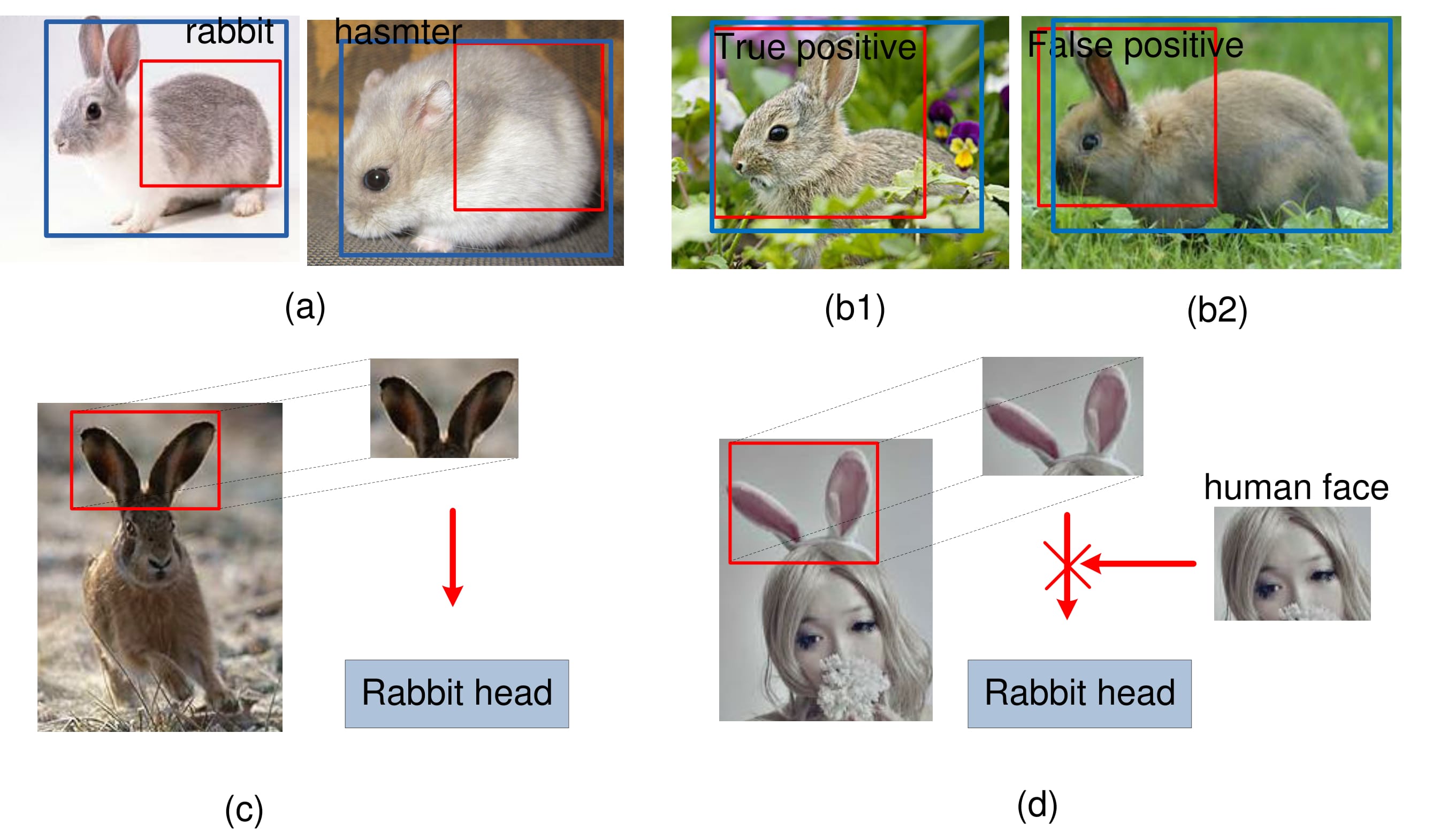
Blue windows indicate the ground truth bounding boxes. Red windows are candidate boxes. It is hard to classify candidate boxes which cover parts of objects because of similar local visual cues in (a) and ignorance on the occlusion status in (b). Local details of rabbit ears are useful for recognizing the rabbit head in (c). The contextual human head help to find that the rabbit ear worn on human head should not be used to validate the existence of the rabbit head in (d).
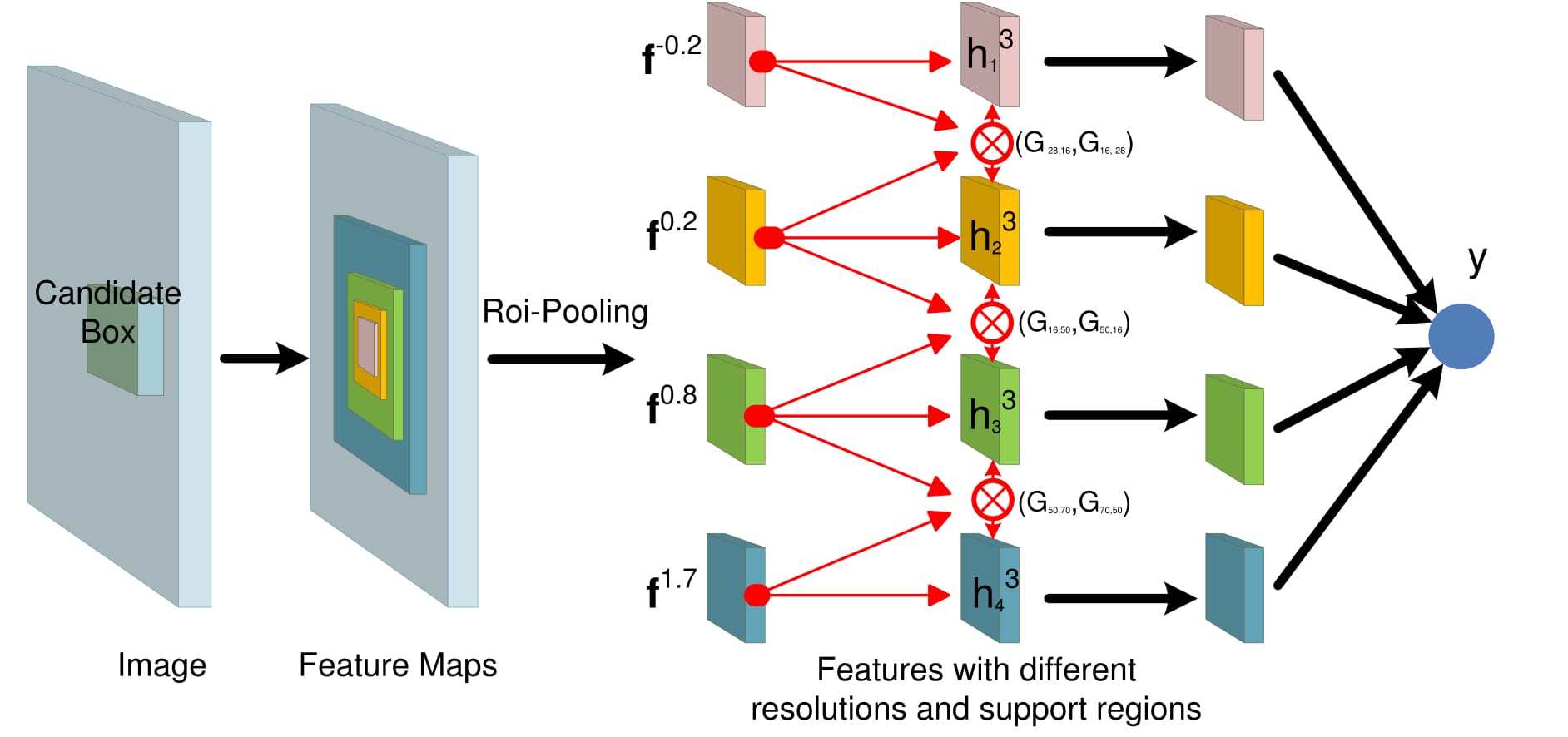
The network takes an image as input and produces feature maps. The roi-pooling is done on feature maps to obtain features with different resolutions and support regions, denoted by -0.2, 0.2, 0.8 and 1.7. Red arrows denote our gated bi-directional structure for passing messages among features. Gate functions G are defined for controlling the message passing rate. Then all features h^3_i for i = 1, 2, 3, 4 go through multiple CNN layers with shared parameters to obtain the final features that are used to predict the class y. Parameters on black arrows are shared across branches, while parameters on red arrows are not shared.
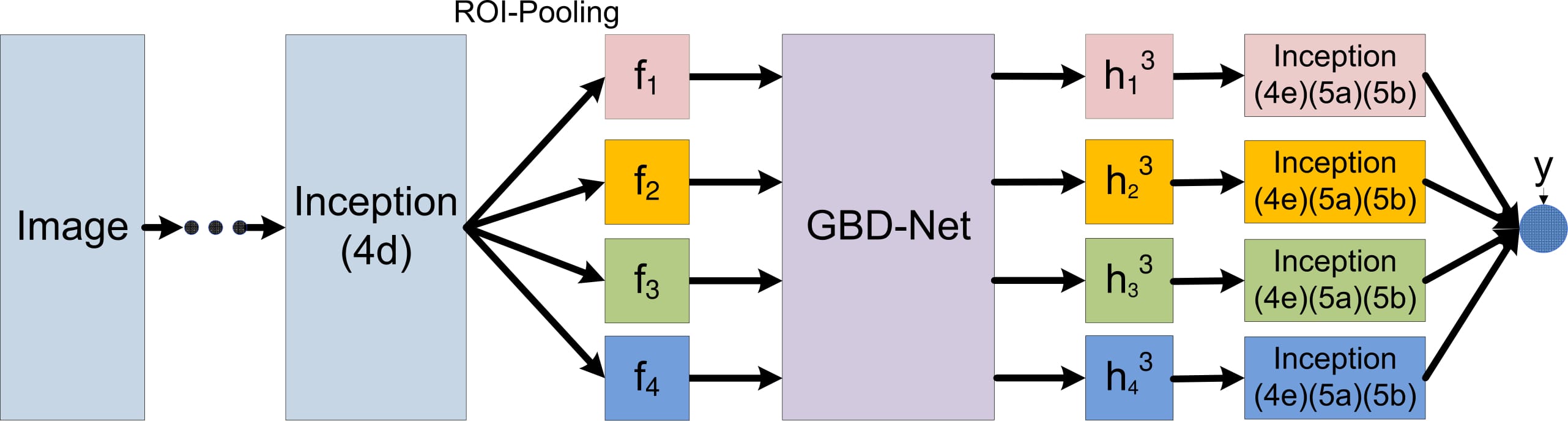
The gated bi-directional network, dedicated as GBD-Net, is placed between Inception (4d) and Inception (4e). Inception (4e),(5a) and (5b) are shared among all branches.
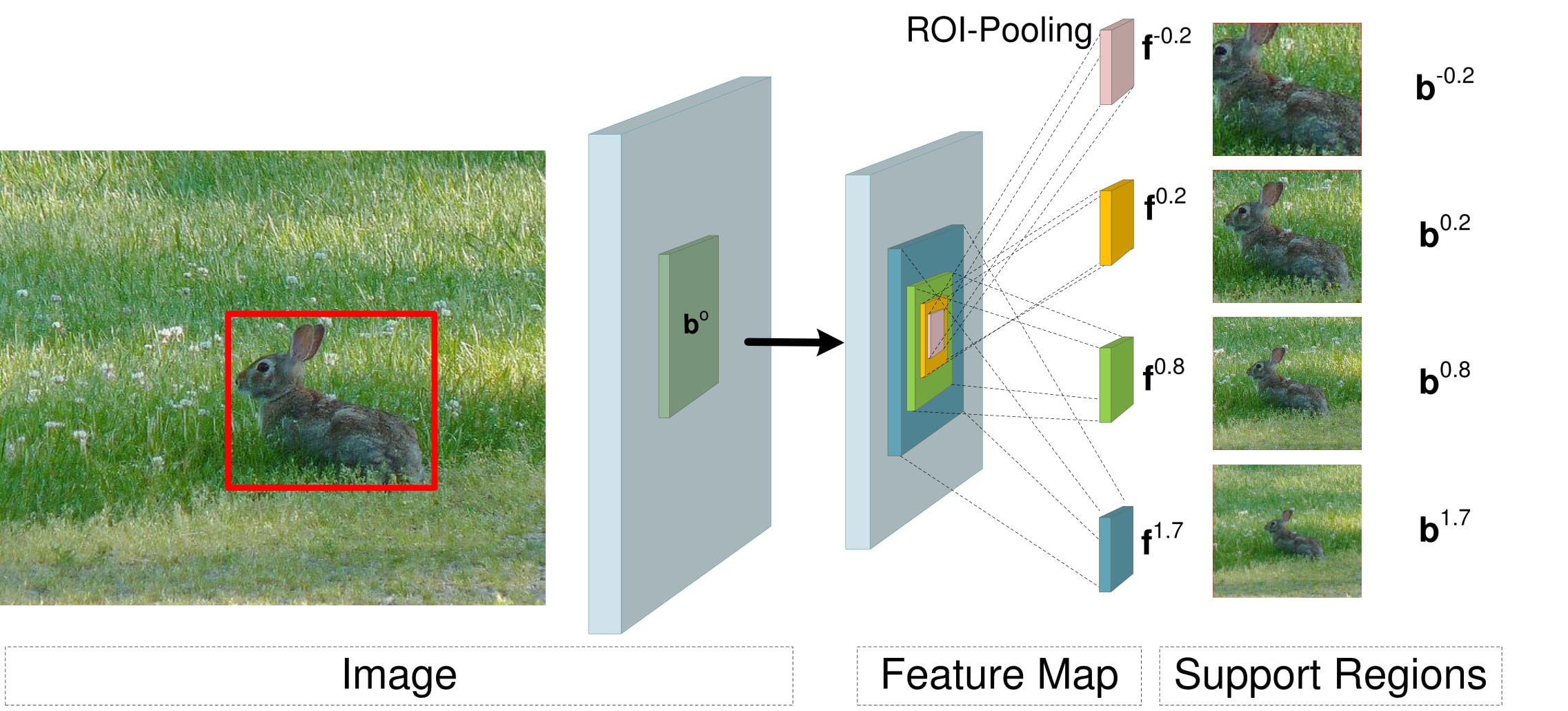
The red rectangle in the left image is a candidate box. The right four image patches show the supporting regions for {b^p}.
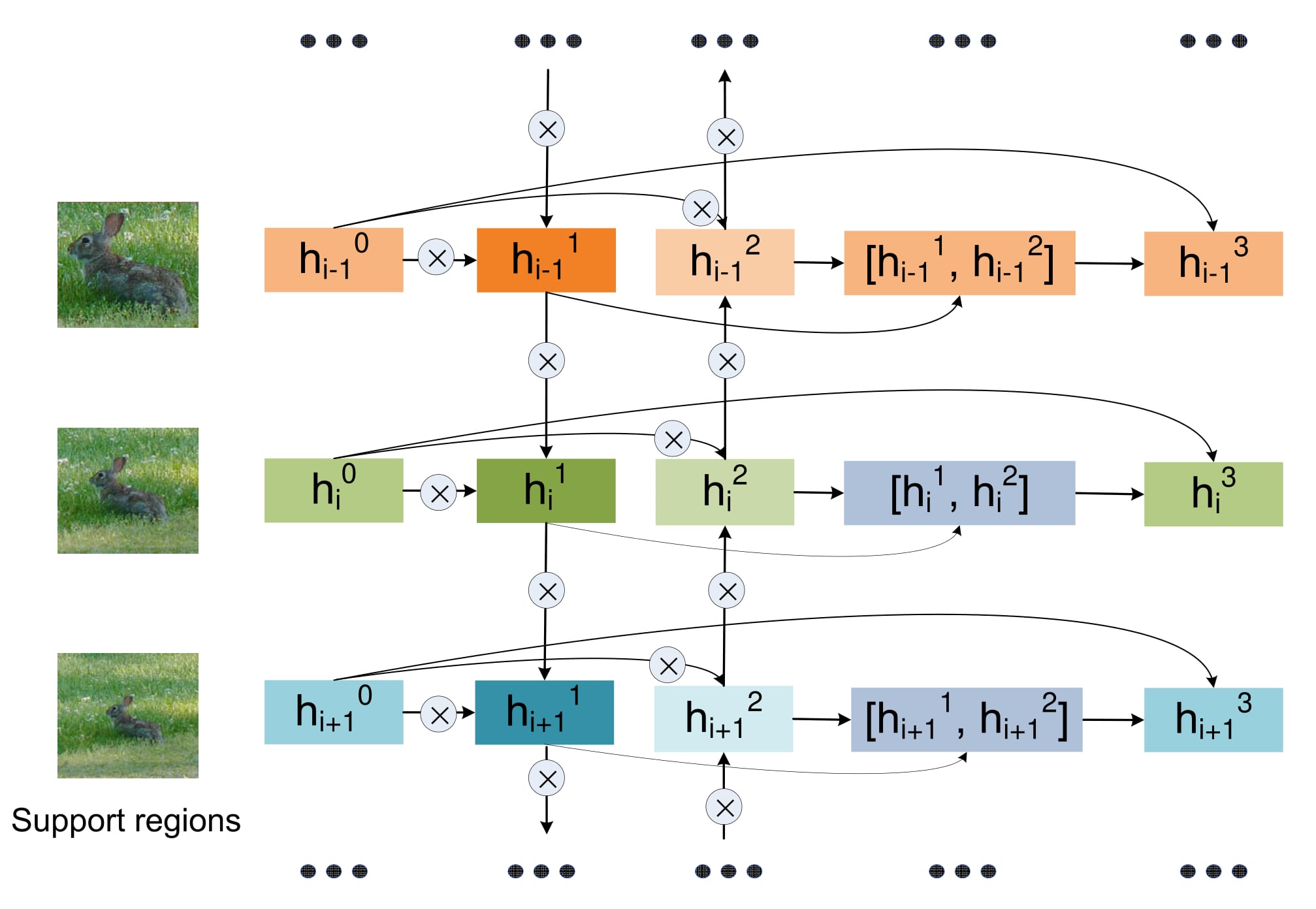
$\otimes$ denotes convolution. The input of this structure is the features {h^0_i} of multiple resolutions and contextual regions. Then bi-directional connections among these features are used for passing messages across resolutions/contexts. The output h^3_{i} are updated features for different resolutions/contexts after message passing.
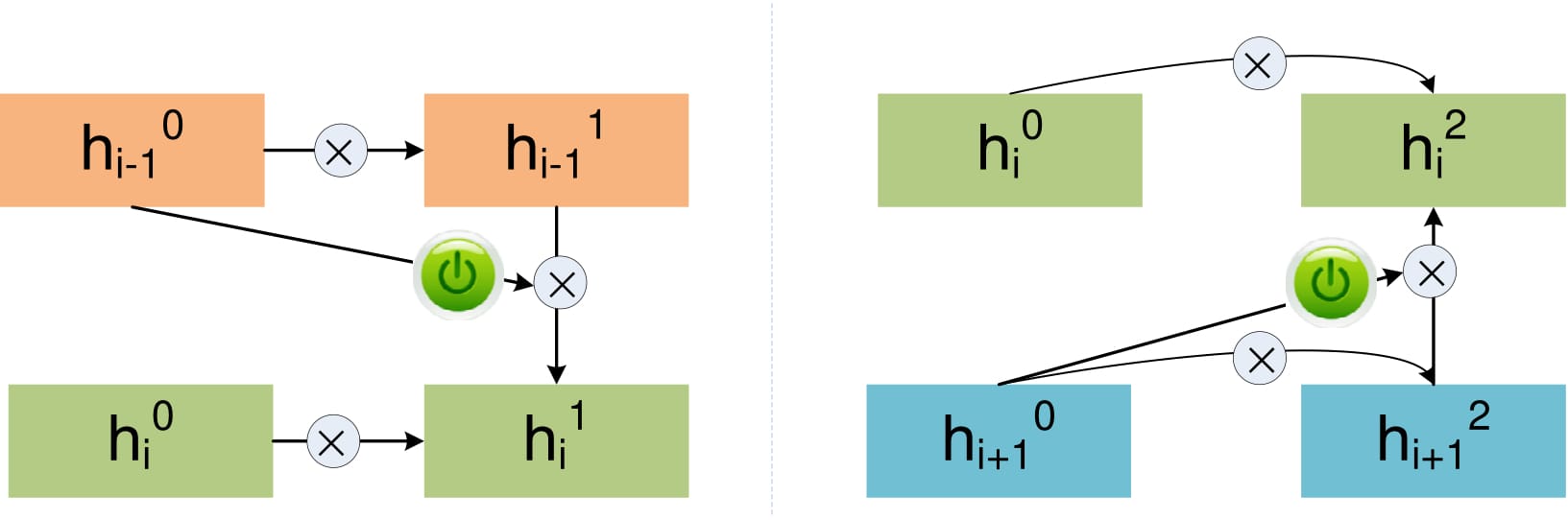
The $\otimes$ represents the convolution and the switch button represents the gate function.

Building blocks are the identity mapping blocks, with the numbers of blocks stacked. Downsampling is performed by conv3_1, conv4\_1, and conv5\_1 with a stride of 2.

Compared with the original stucture, an identity mapping layer is added from h_*^0 to h_*^3. The convolution from [h_*^1, h_*^2]$ to h_*^3 is changed into max-pooling.
Codes
Please find our code here.
Citation
If you use our codes or dataset, please cite the following papers:
- Xingyu Zeng, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang. "Gated Bi-directional CNN for Object Detection", European Conference on Computer Vision(ECCV). Springer International Publishing, 2016.
- Zeng, Xingyu, Wanli Ouyang, Junjie Yan, Hongsheng Li, Tong Xiao, Kun Wang, Yu Liu et al. "Crafting GBD-Net for Object Detection." arXiv preprint arXiv:1610.02579 (2016).