
Introduction
We propose deformable deep convolutional neural networks for generic object detection. This new deep learning object detection framework has innovations in multiple aspects. In the proposed new deep architecture, a new deformation constrained pooling (def-pooling) layer models the deformation of object parts with geometric constraint and penalty. A new pre-training strategy is proposed to learn feature representations more suitable for the object detection task and with good generalization capability. By changing the net structures, training strategies, adding and removing some key components in the detection pipeline, a set of models with large diversity are obtained, which significantly improves the effectiveness of model averaging. The proposed approach improves the mean averaged precision obtained by RCNN, which was the state-ofthe-art, from 31% to 50.3% on the ILSVRC2014 detection test set. It also outperforms the winner of ILSVRC2014, GoogLeNet, by 6.1%. Detailed component-wise analysis is also provided through extensive experimental evaluation, which provide a global view for people to understand the deep learning object detection pipeline
Contribution Highlights
- A new deep learning framework for object detection. It effectively integrates feature representation learning, part deformation learning, context modeling, model averaging, and bounding box location refinement into the detection system. Detailed component-wise analysis is provided through extensive experimental evaluation. This paper is also the first to investigate the influence of CNN structures for the large-scale object detection task under the same setting. By changing the configuration of this framework, multiple detectors with large diversity are generated, which leads to more effective model averaging.
- A new scheme for pretraining the deep CNN model. We propose to pretrain the deep model on the ImageNet image classification and localization dataset with 1000-class object-level annotations instead of with image-level annotations, which are commonly used in existing deep learning object detection [14, 44]. Then the deep model is fine-tuned on the ImageNet/PASCAL-VOC object detection dataset with 200/20 classes, which are the targeting object classes in the two datasets.
- A new deformation constrained pooling (def-pooling) layer, which enriches the deep model by learning the deformation of object parts at any information abstraction levels. The def-pooling layer can be used for replacing the max-pooling layer and learning the deformation properties of parts.
Citation
If you use our codes or dataset, please cite the following papers:
- Ouyang, Wanli, et al. "Deepid-net: Deformable deep convolutional neural networks for object detection." CVPR. 2015. PDF
Images
(a) and jointly learning feature representation and deformable object parts shared by multiple object classes at different semantic levels (b). In (a), a model pretrained on image-level annotation is more robust to size and location change while a model pretrained on object-level annotation is better in representing objects with tight bounding boxes. In (b), when ipod rotates, its circular pattern moves horizontally at the bottom of the bounding box. Therefore, the circular patterns have smaller penalty moving horizontally but higher penalty moving vertically. The curvature part of the circular pattern are often at the bottom right positions of the circular pattern.
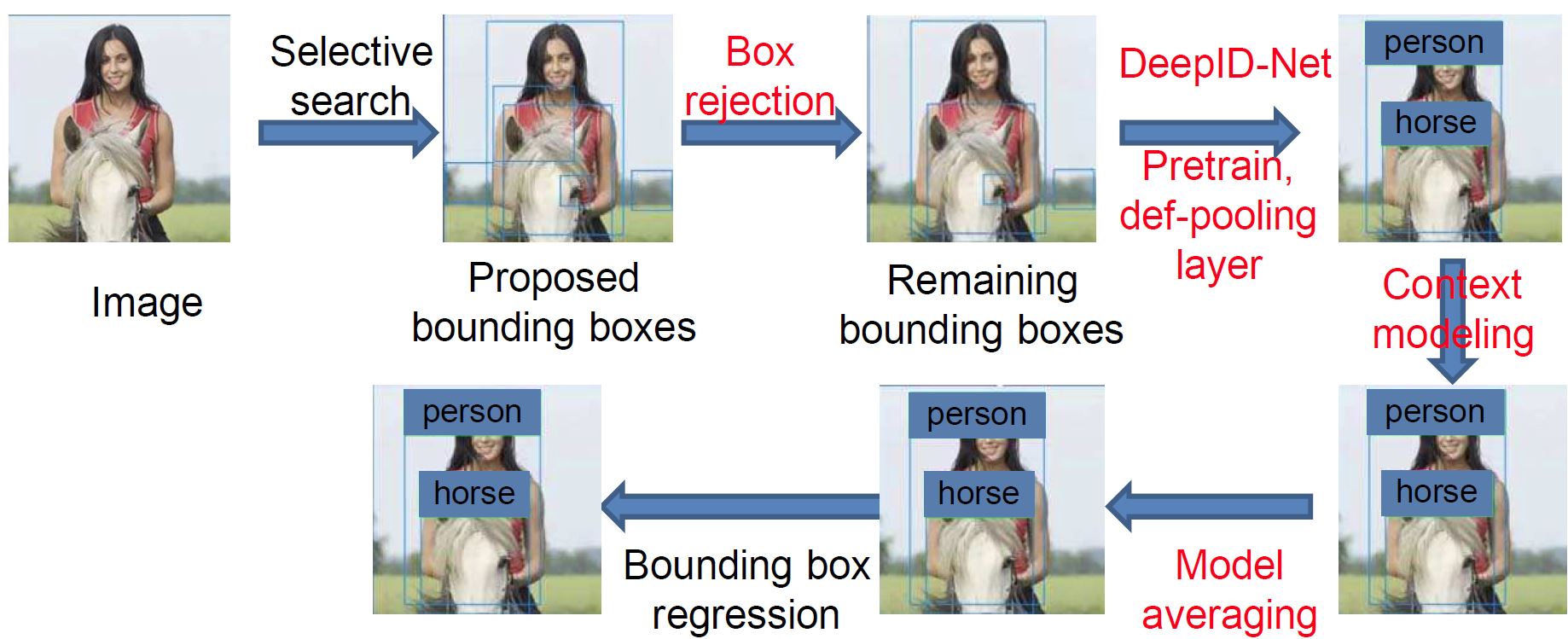
Texts in red highlight the steps that are not present in RCNN
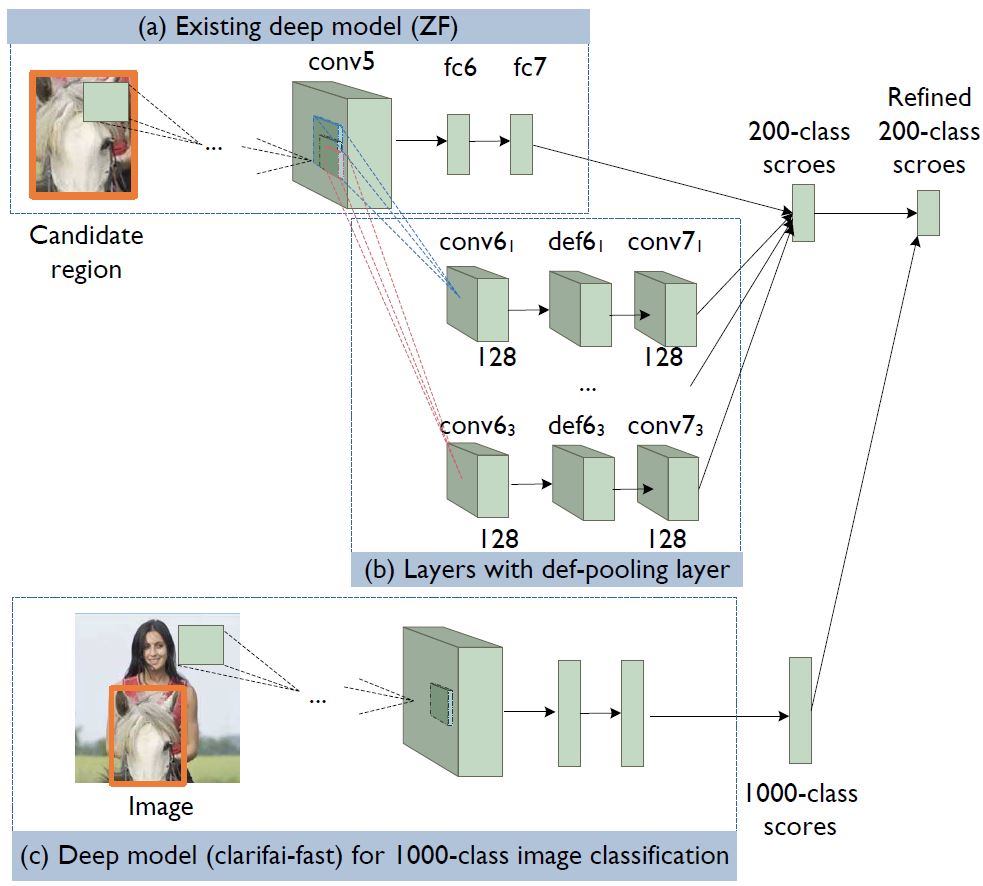
(a) baseline deep model, which is ZF in our best-performing singlemodel detector; (b) layers of part filters with variable sizes and defpooling layers; (c) deep model to obtain 1000-class image classification scores. The 1000-class image classification scores are used to refine the 200-class bounding box classification scores.
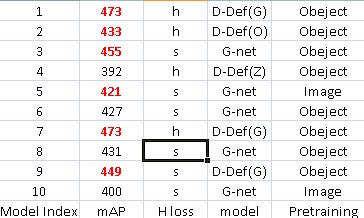
The 10 models used for model averaging selection. The selected models are highlighted in red. The result of mAP is on val2 without bounding box regression and context. For net design, D-Def(O) denotes our DeepID-Net that uses def-pooling layers using Overfeat as baseline structure, D-Def(G) denotes DeepID-Net that uses def-pooling layers using GoogLeNet as baseline structure, G-net denotes GoogLeNet. For pretraining, image denotes the image-centric pretraining scheme of RCNN, object denotes the object centric Scheme 1 in Section \ref{Sec:Prtrain}. For loss of net, h denotes hinge loss, s denotes softmax loss. Bounding box rejection is used for all models. Selective search and edgeboxes are used for proposing regions.
Models
| Net Structure | Pre-training Scheme | Pretrained Model (on ImageNet Cls data) | Finetuned Model (on ImageNet Det data) |
| AlexNet | Image-level Annotations | Download | Download |
| AlexNet | Object-level Annotations | Download | Download |
| Clarifai | Image-level Annotations | Download | Download |
| Clarifai | Object-level Annotations | Download | Download |
| Overfeat | Image-level Annotations | Download | Download |
| Overfeat | Object-level Annotations | Download | Download |
| GoogleNet | Image-level Annotations | Download | Download |
| GoogleNet | Object-level Annotations | Download | Download |
Object detection demo code
Slides on the ImageNet 2014 Chanllenge